Athena Spark
Athena Spark
Trong hội thảo này, chúng ta sẽ khám phá các tính năng của Amazon Athena for Apache Spark và chạy các phòng thí nghiệm thực hành thể hiện các tính năng và biện pháp thực hành tốt nhất. Vào cuối hội thảo, bạn sẽ có thể:
Tạo nhóm làm việc Amazon Athena với Spark làm công cụ phân tíchTạo sổ ghi chép và chạy tính toán trong sổ ghi chépSử dụng nhật ký Cloudwatch để theo dõi và gỡ lỗi
Amazon Athena for Apache Spark cung cấp các phân tích tương tác dưới một giây để phân tích hàng petabyte dữ liệu bằng cách sử dụng khung Spark nguồn mở. Các ứng dụng Spark tương tác bắt đầu ngay lập tức và chạy nhanh hơn với thời gian chạy Spark được tối ưu hóa của chúng tôi, vì vậy bạn dành nhiều thời gian hơn cho thông tin chi tiết chứ không phải chờ đợi kết quả. Xây dựng các ứng dụng Spark bằng cách sử dụng tính biểu cảm của Python với trải nghiệm sổ ghi chép được đơn giản hóa trong bảng điều khiển Athena hoặc thông qua API Athena. Với mô hình phi máy chủ, được quản lý toàn phần, không có tài nguyên để quản lý, cung cấp và cấu hình cũng như không có phí hoặc chi phí thiết lập tối thiểu. Bạn chỉ phải trả tiền cho các truy vấn mà bạn chạy.
Kiến thức về Spark , Python / Scala rất hữu ích nhưng không phải là điều kiện tiên quyết cho hội thảo này
- Bạn tải xuống Notebook
Tạo Spark workgroup và Notebook
- Truy cập bảng điều khiển Athena Notebook
- Tạo Spark workgroup
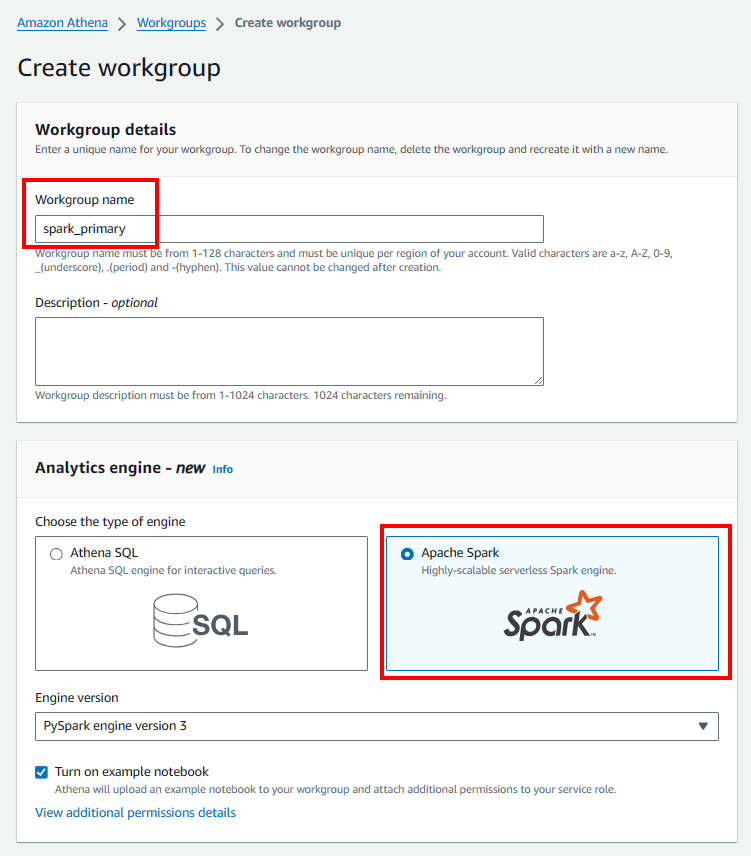
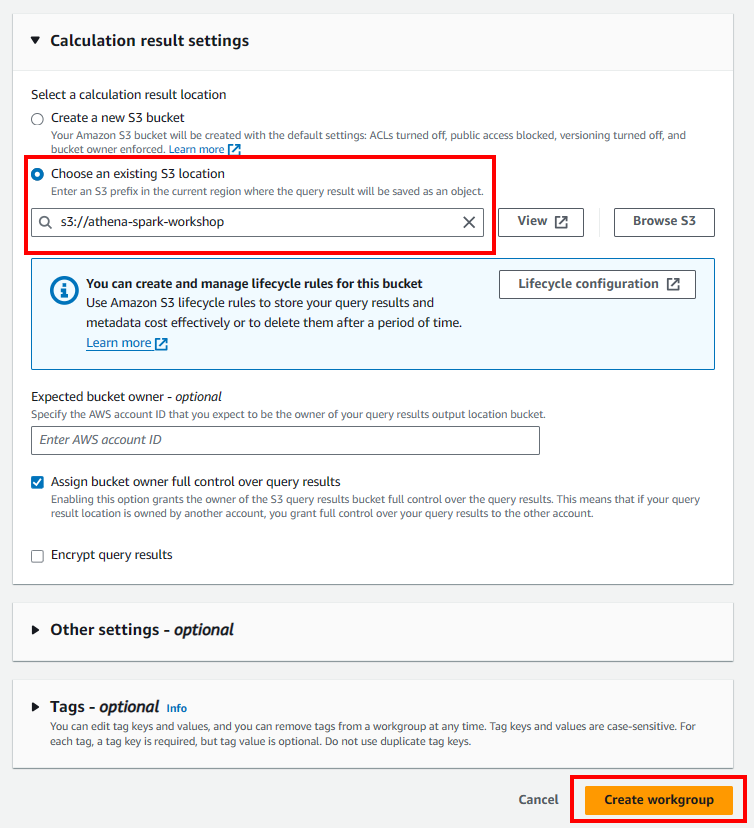
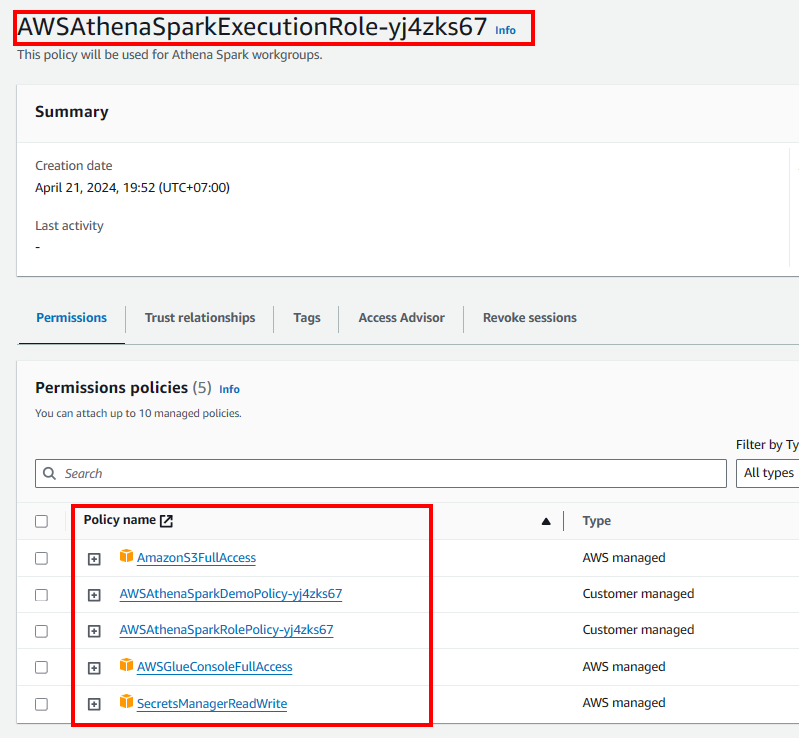
Cập nhật vai trò IAM của Athena Spark
- Truy cập Bảng điều khiển IAM.
- Trên thanh điều hướng bên trái, hãy chọn Roles
- Chọn Vai trò được tạo bởi Athena
- Thêm tất cả quyền chúng tôi cần
Execute Notebook
-
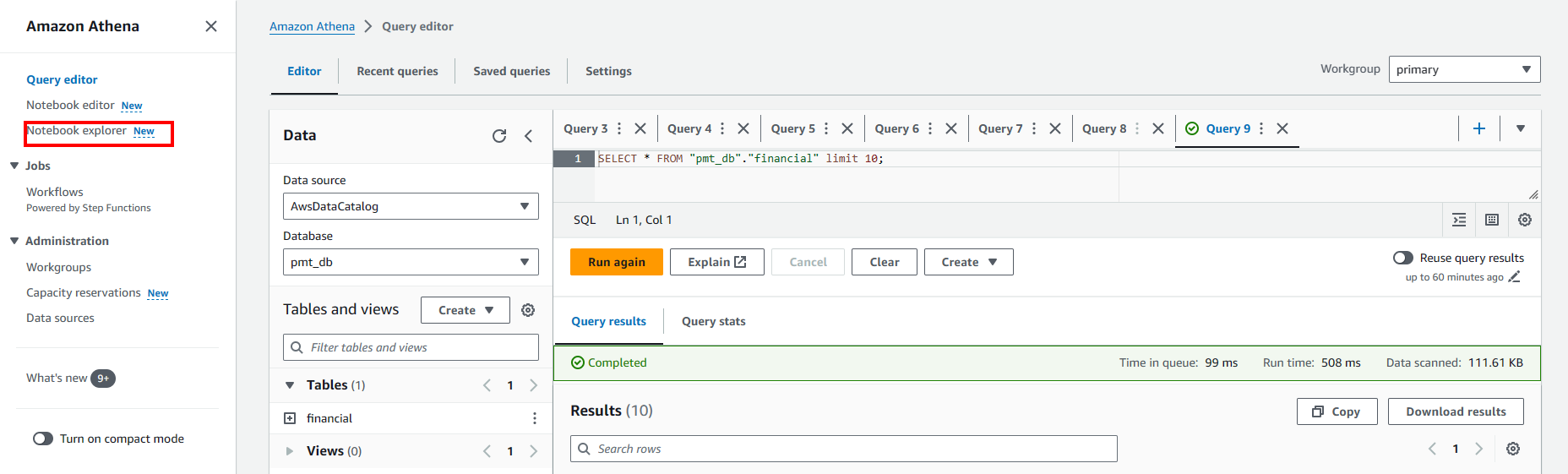
Import Notebook:
- Truy cập Notebook explorer.
- Chọn Import file
- Tải lên notebook của bạn
-
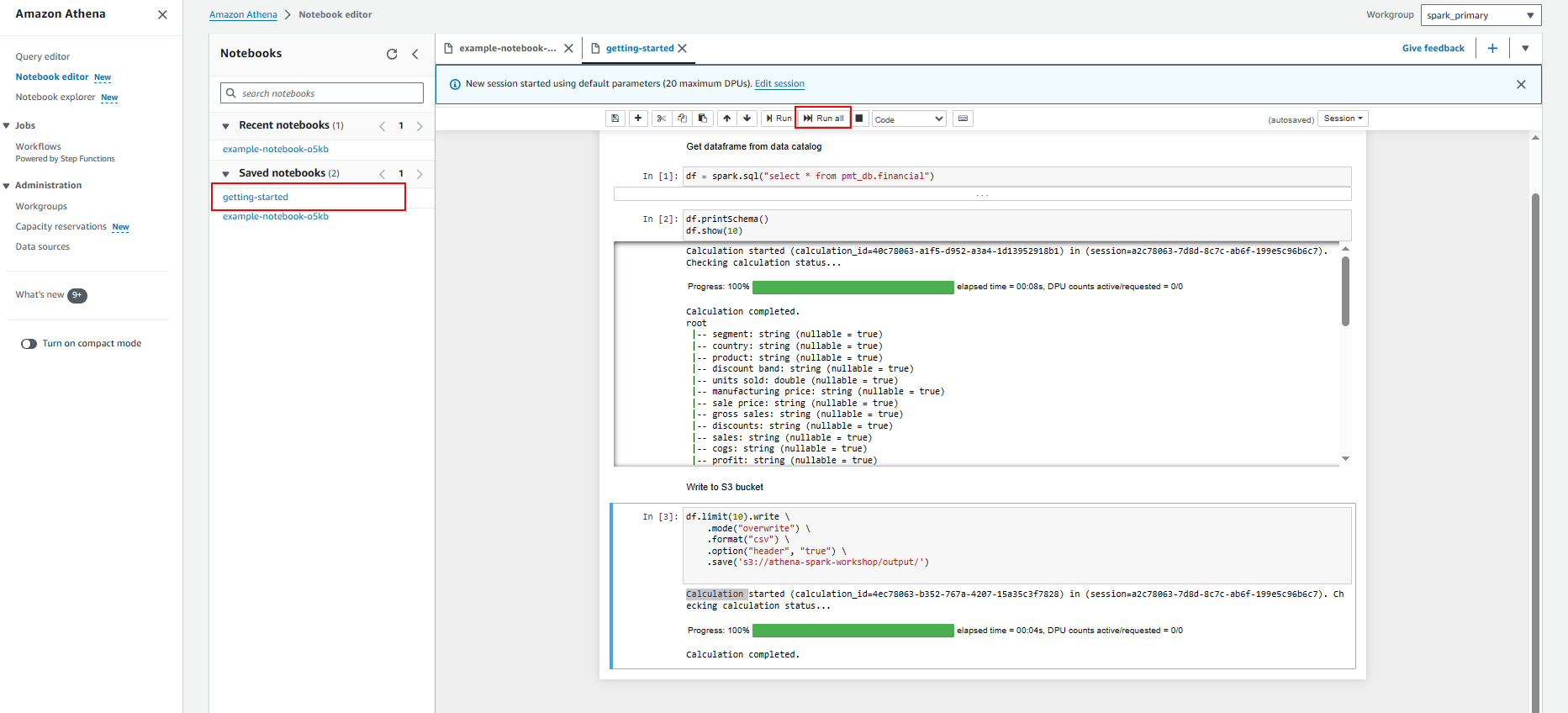
Bắt đầu truy vấn trong notebook
- Tải Dataframe từ glue data catalog
-
Chuẩn bị và khám phá dữ liệu
Trong Phòng thực hành này, chúng tôi sẽ hướng dẫn cách sử dụng Amazon Athena for Apache Spark để chạy phân tích và khám phá dữ liệu một cách tương tác mà không cần lập kế hoạch, cấu hình hoặc quản lý tài nguyên.
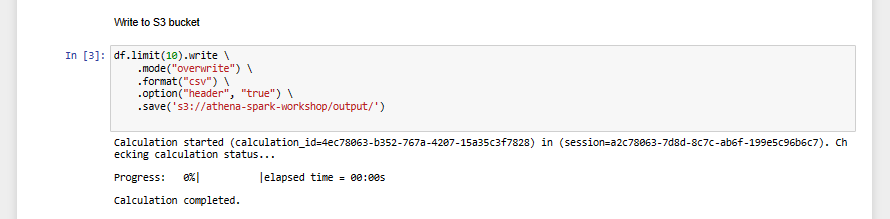
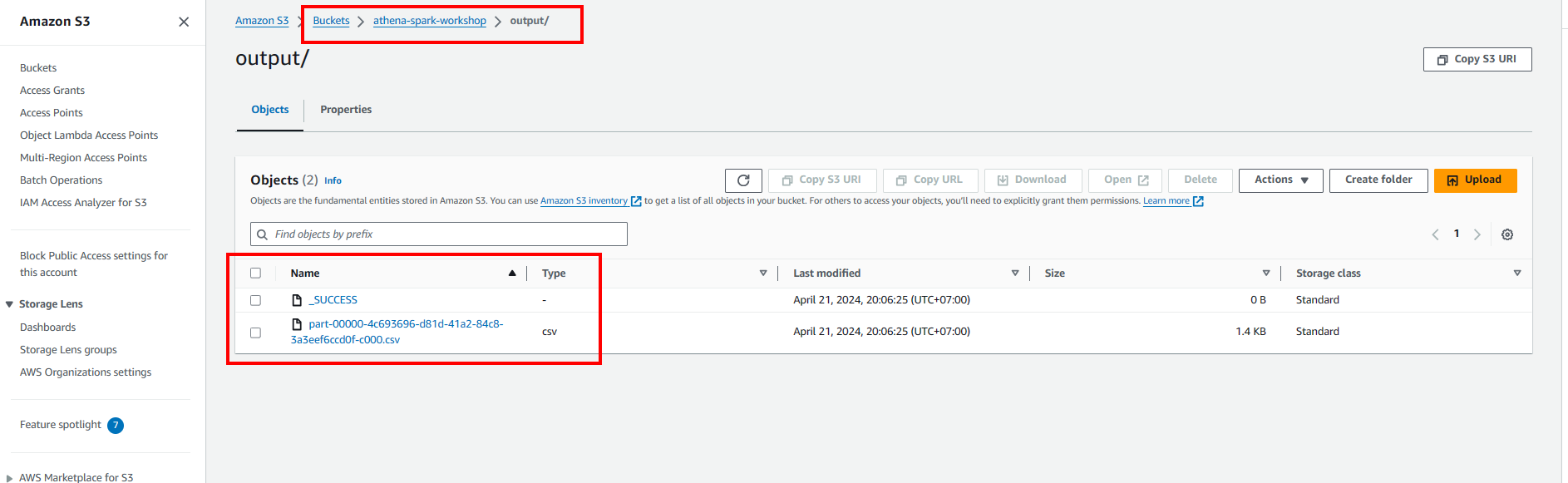
- Ghi vào S3 bucket
- Phân tích dữ liệu từ Government
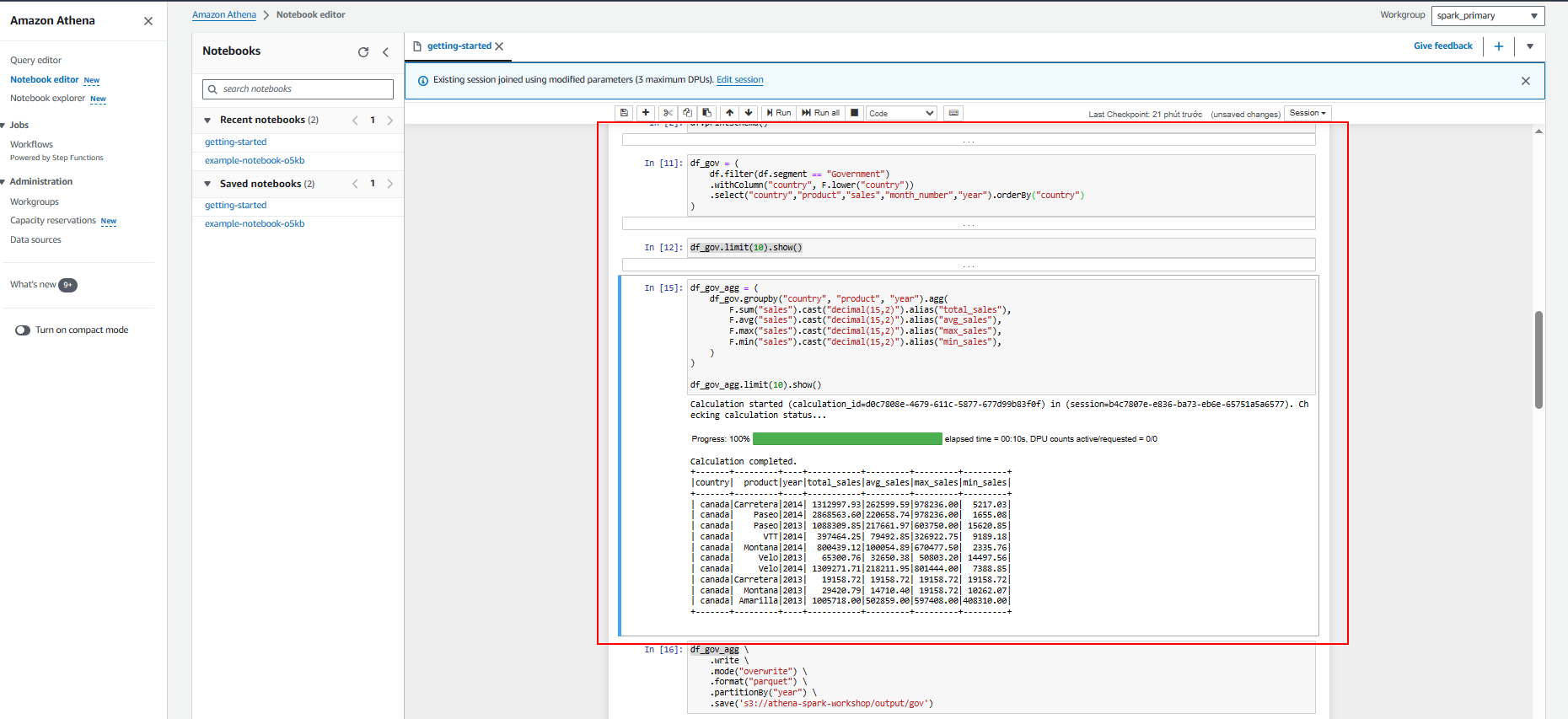
- Tạo bảng trong glue data catalog. Vì vậy, chúng tôi cũng có thể truy vấn dữ liệu bằng cách sử dụng Athena Query Editor.
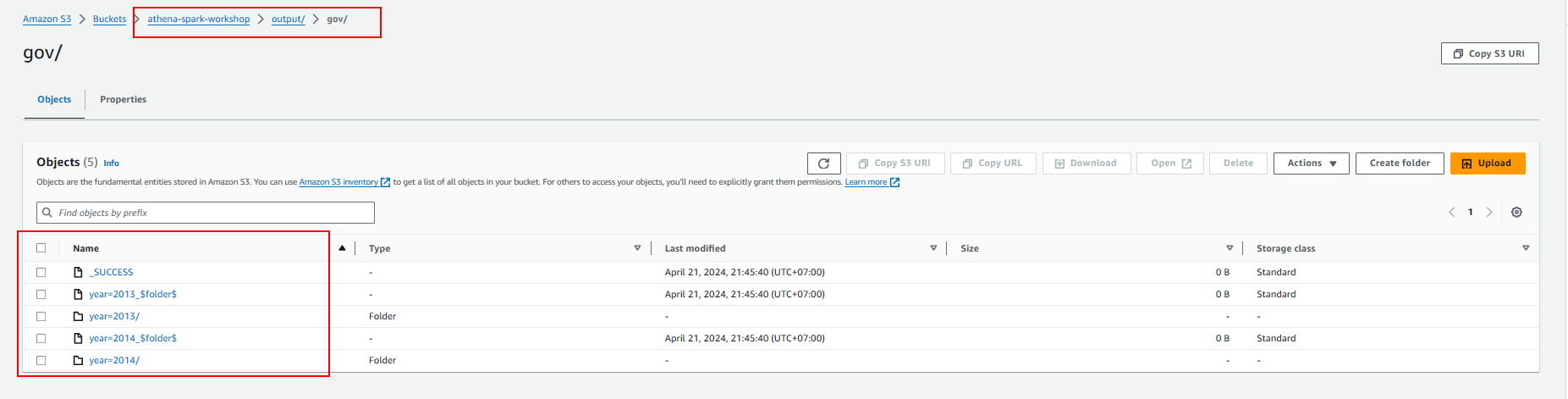
-
Xây dựng trực quan hóa
Trong phòng thực hành này, chúng tôi sẽ hướng dẫn cách xây dựng trực quan hóa trong Amazon Athena cho Apache Spark bằng Matplotlib và Seaborn.
Matplotlib là một thư viện toàn diện để tạo trực quan hóa tĩnh, hoạt hình và tương tác trong Python. Matplotlib giúp:
- Tạo publication quality plots .
- Làm số liệu tương tác có thể thu phóng, xoay, cập nhật.
- Tùy chỉnh visual style and layout .
- Xuất sang [nhiều định dạng tệp] (https://matplotlib.org/stable/api/figure_api.html#matplotlib.figure.Figure.savefig) .
- Nhúng vào [JupyterLab và giao diện người dùng đồ họa] (https://matplotlib.org/stable/gallery/#embedding-matplotlib-in-graphical-user-interfaces) .
- Sử dụng một mảng phong phú gồm gói của bên thứ ba được xây dựng trên Matplotlib.
Seaborn là một thư viện để tạo đồ họa thống kê bằng Python. Nó được xây dựng trên matplotlib và tích hợp chặt chẽ với pandas cấu trúc dữ liệu.
- Sử dụng Seaborn để xây dựng trực quan hóa trên dữ liệu này
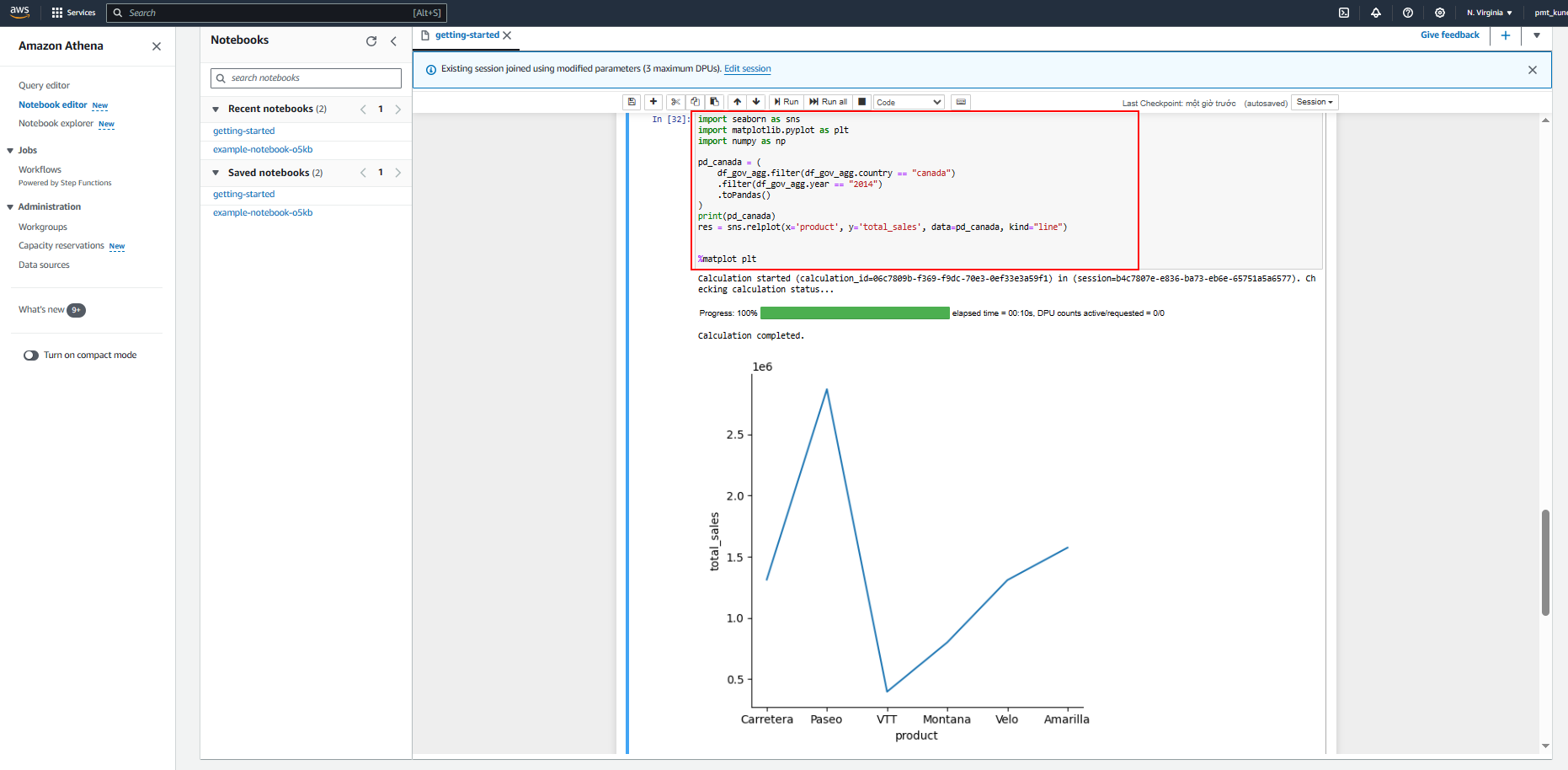
- Xây dựng trực quan hóa bằng Matplotlib
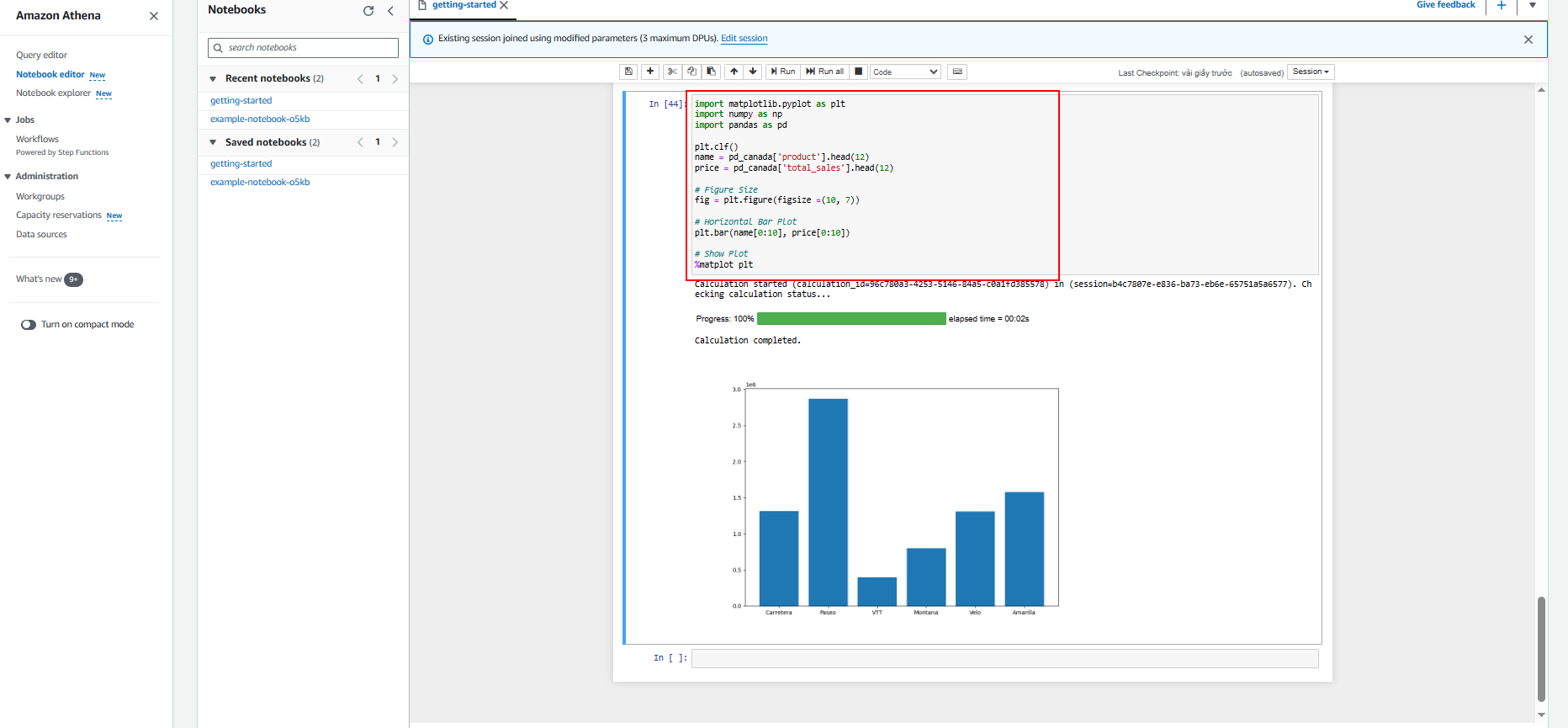
-
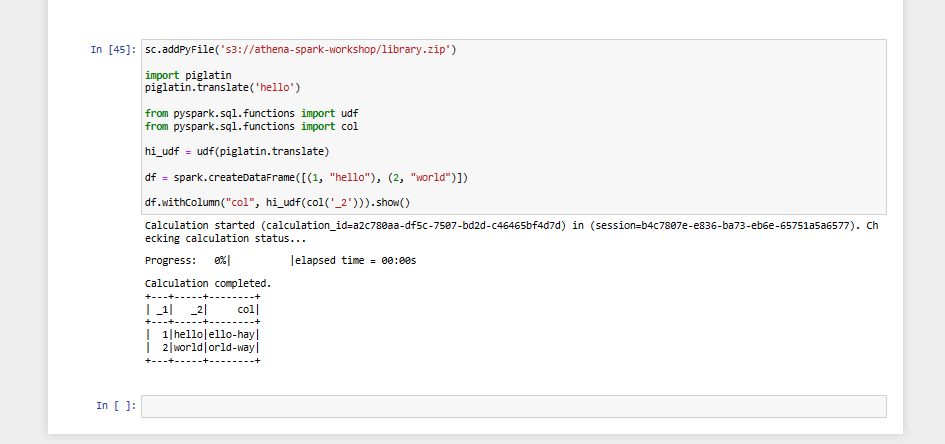
Cài đặt các thư viện Python bổ sung Trong phòng thực hành này, chúng tôi sẽ hướng dẫn cách nhập các thư viện Python bổ sung vào Amazon Athena cho Apache Spark. Chúng ta sẽ sử dụng lệnh pip để tải xuống tệp .zip Python của dự án bpabel/piglatin từ Python Package Index PyPI.
- Truy cập AWS Cloud9.
- Truy cập môi trường của bạn
mkdir testpiglatin cd testpiglatin virtualenv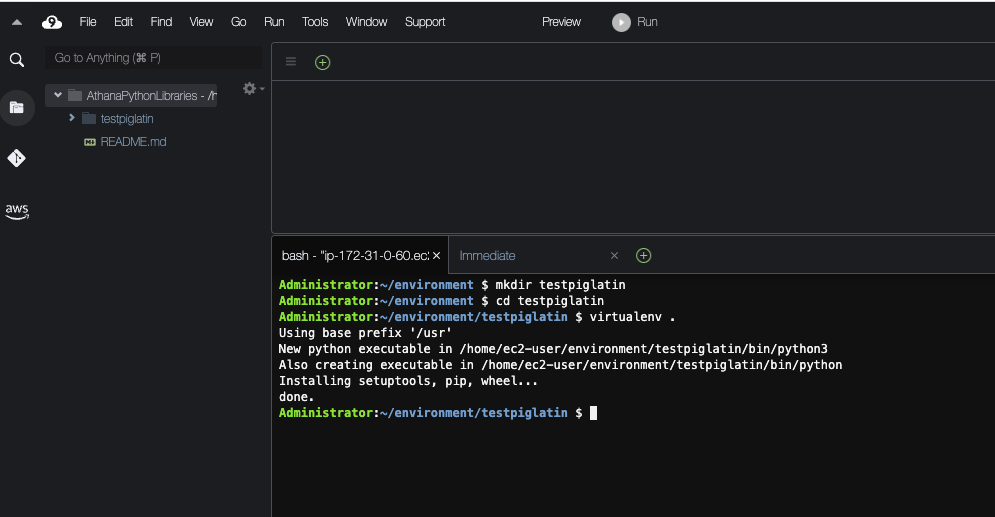
- Tạo một thư mục con có tên đã giải nén để giữ dự án và Sử dụng lệnh pip để cài đặt dự án vào thư mục đã giải nén
mkdir unpacked pip install -t $PWD/unpacked piglatin
- Thay đổi thư mục đã giải nén và hiển thị nội dung.
cd unpacked ls
- Sử dụng lệnh zip để đặt nội dung của dự án piglatin vào một tệp có tên library.zip, điều này sẽ được tạo trong thư mục testpiglatin.
zip -r9 ../library.zip *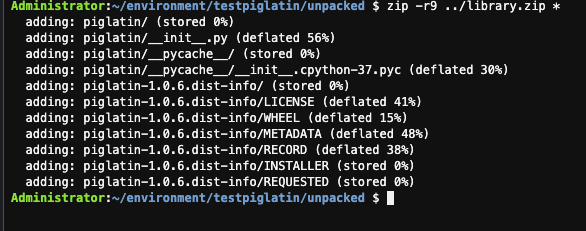
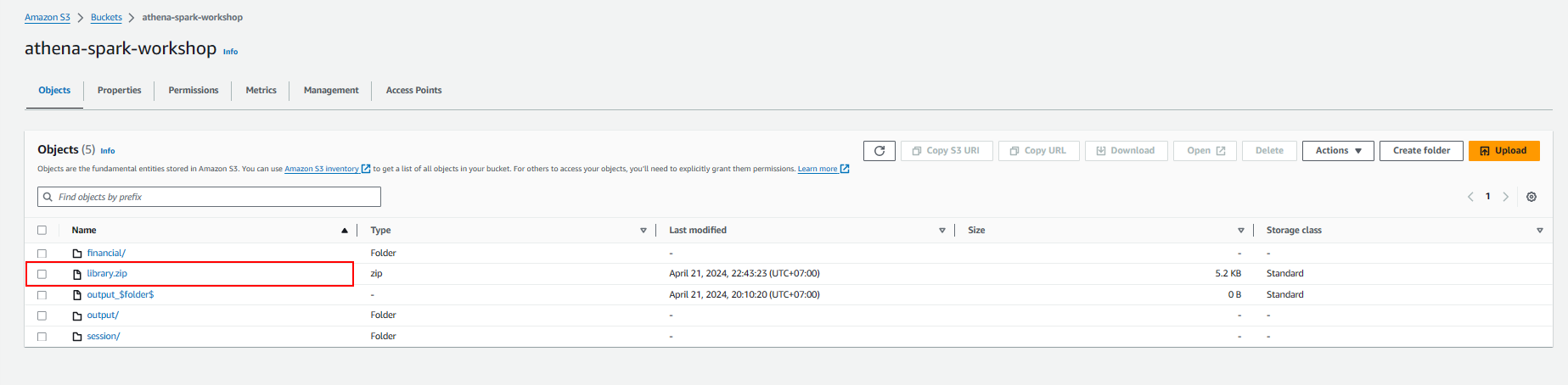
- Sao chép tệp library.zip vào vùng lưu trữ Amazon S3 được tạo trong Tài khoản AWS của bạn,
cd .. ls aws s3 cp library.zip s3://athena-spark-workshop
- Execute notebook
-
Kiểm tra chi tiết phiên
Trong phòng thực hành này, chúng tôi sẽ chỉ ra cách khám phá lịch sử phiên thời gian chạy Athena và chi tiết tính toán của nó, bao gồm thời điểm phiên bắt đầu và số lượng DPU (Đơn vị xử lý dữ liệu) mà nó đã tiêu thụ và danh sách các phép tính mà nó đã thực hiện cùng với tổng thời gian chạy, v.v. Có hai cách bạn có thể khám phá chi tiết phiên, một cách sử dụng Notebook explorer và một cái khác sử dụng Workgroup
Sử dụng Notebook Explorer
-
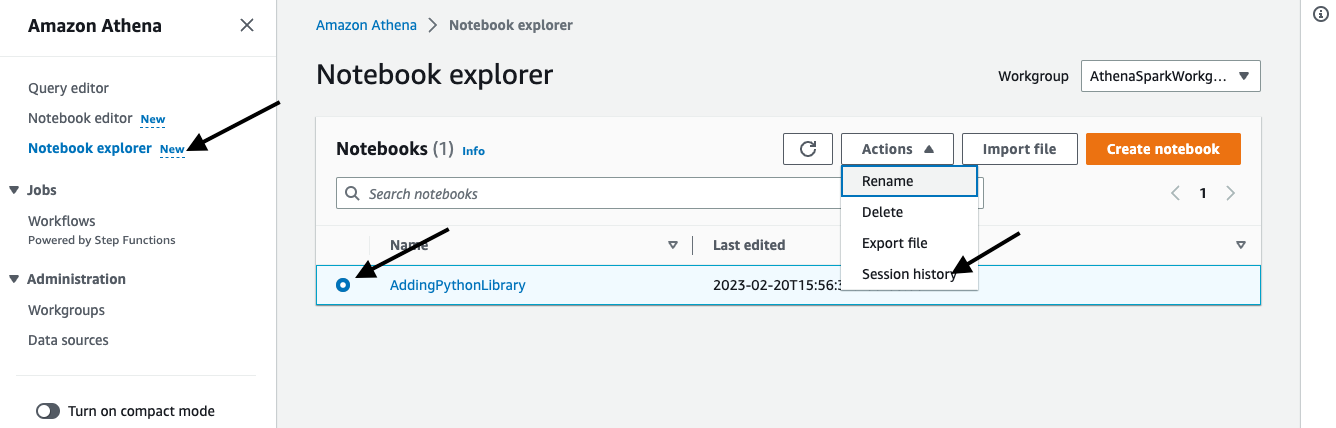
Nhấp vào Notebook explorer trên menu bên và chọn sổ ghi chép bạn đã nhập và nhấp vào Lịch sử phiên từ menu thả xuống Hành động. Điều này sẽ hiển thị danh sách các phiên được đóng thùng cho máy tính xách tay này.
-
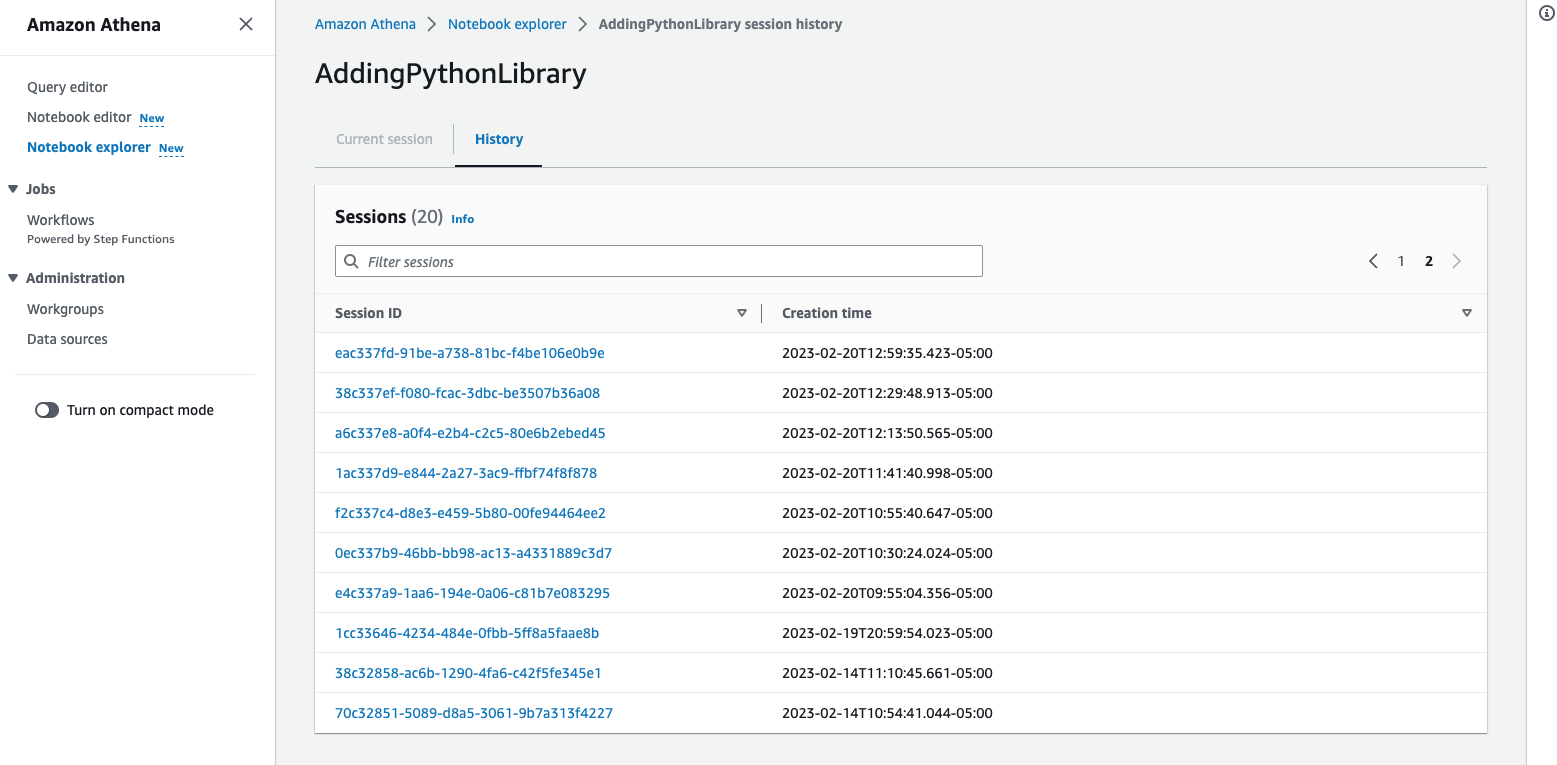
Nhấp vào một trong các ID phiên để xem chi tiết, điều này sẽ hiển thị cho bạn khi phiên bắt đầu, trạng thái phiên và danh sách các phép tính mà nó đã thực hiện từ sổ ghi chép cùng với tổng thời gian chạy cần thiết để hoàn thành phép tính và trạng thái cho dù nó Completed hoặc Failed.
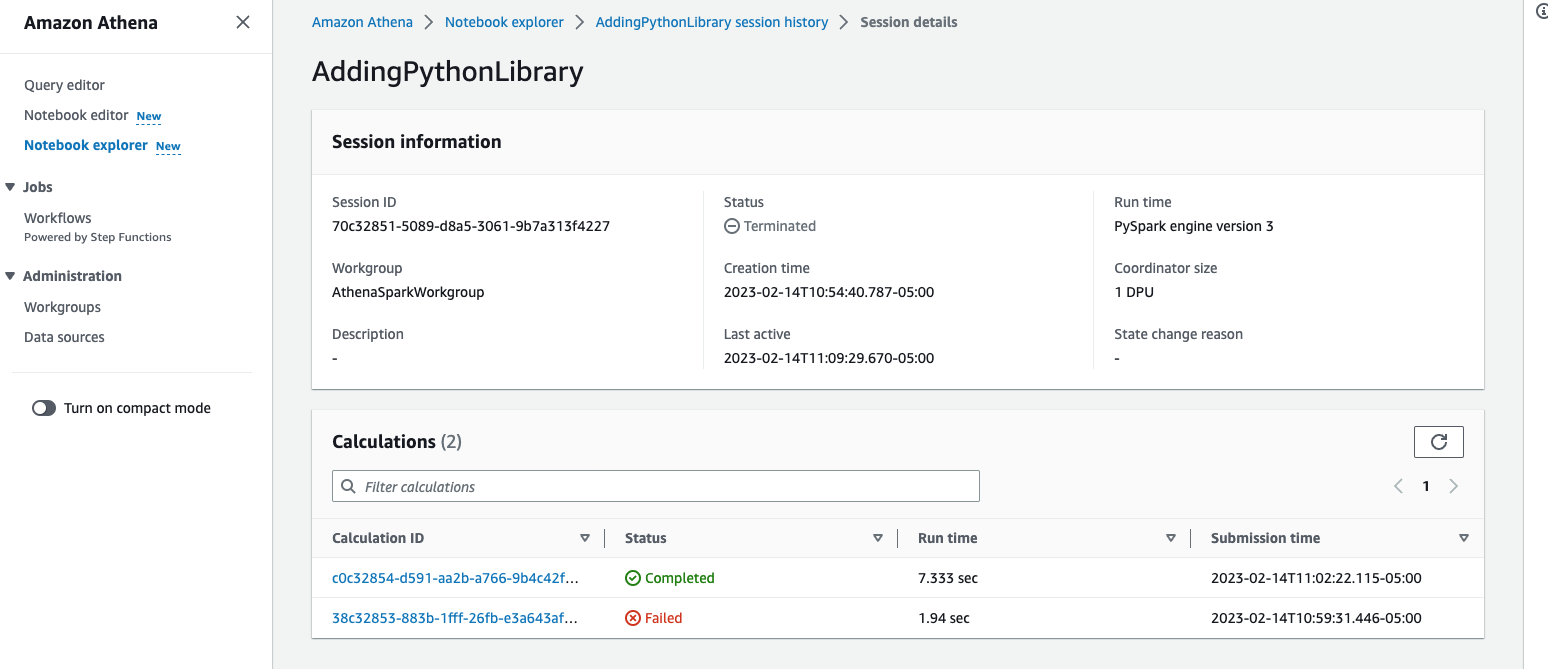
-
Nhấp vào một trong các phép tính để khám phá thêm ô sổ ghi chép nào được thực thi, tổng thời lượng thời gian chạy, mã được thực thi và kết quả, v.v., bạn cũng có thể tải xuống kết quả từ Results.
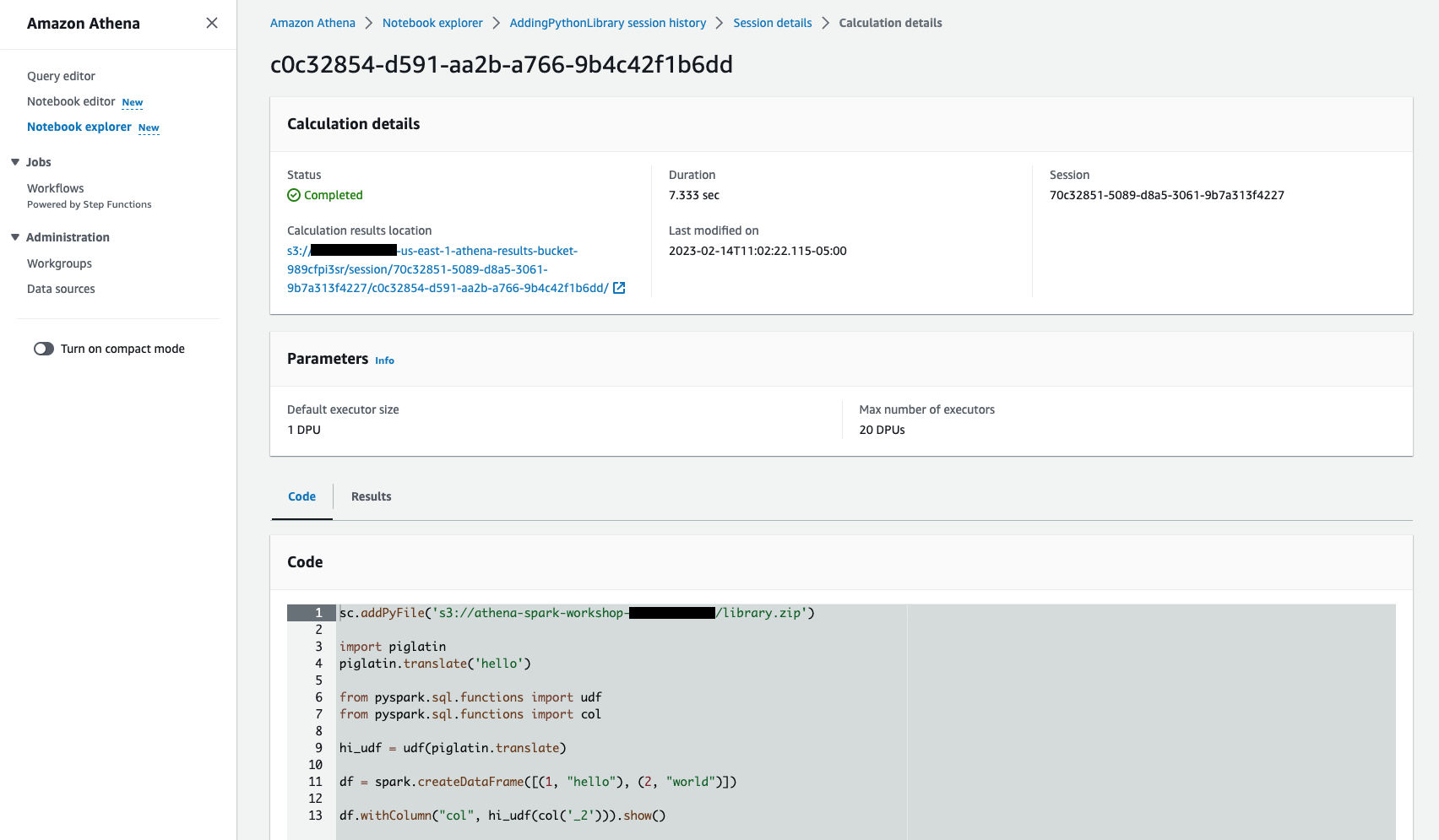
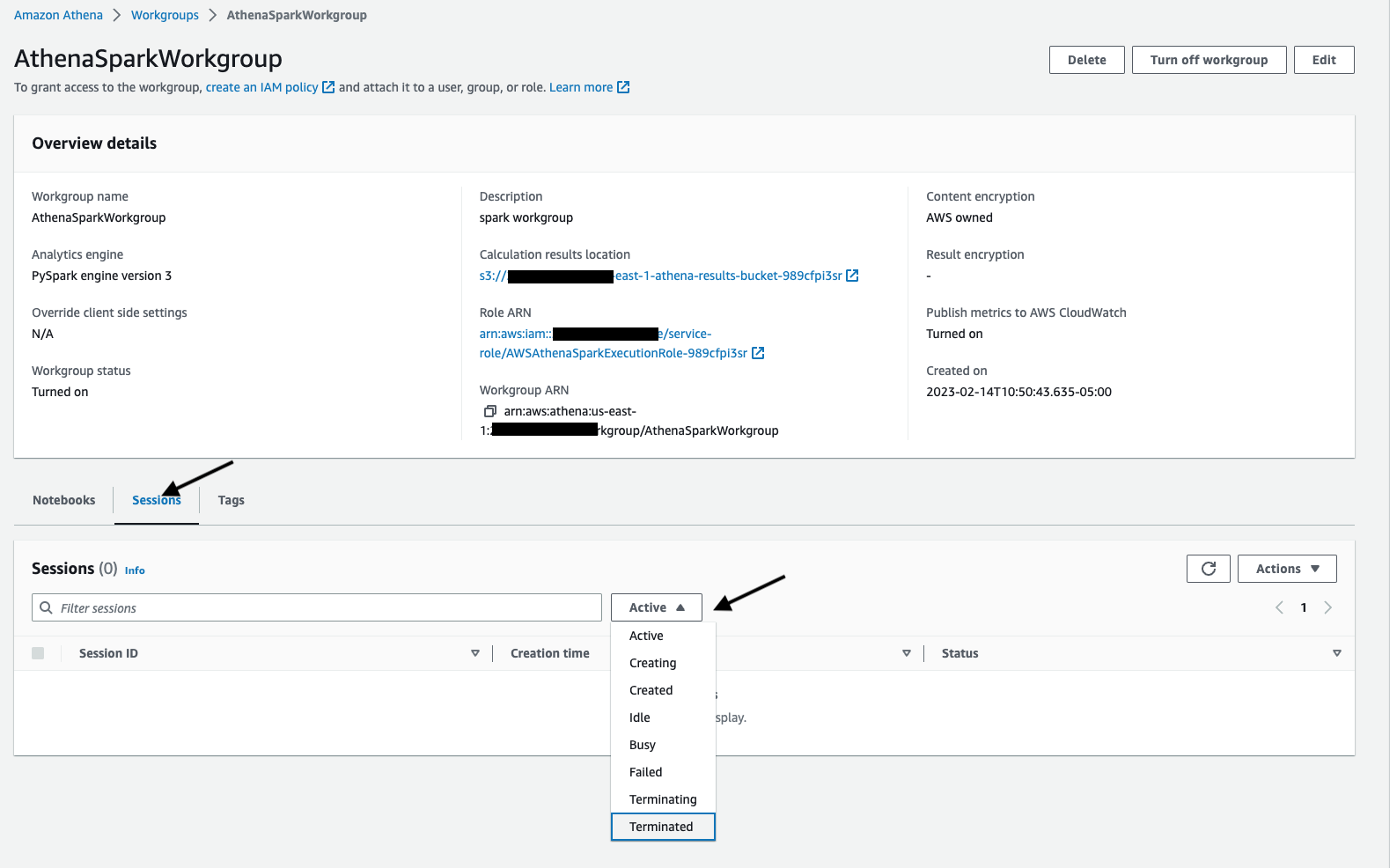
Sử dụng Workgroups
-
Nhấp vào Workgroups bên dưới menu Quản trị
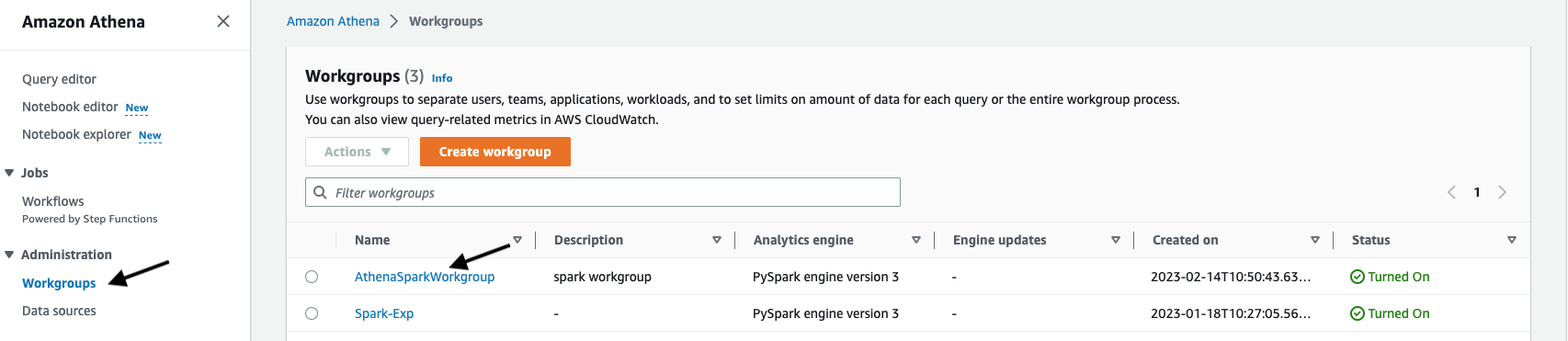
-
Nhấp vào một trong các workgroup bạn tạo cho Spark Analytics engine PySpark engine version 3, Nó sẽ hiển thị như sau: chi tiết Workgroup bao gồm danh sách Notebooks và Sessions liên quan đến workgroup.
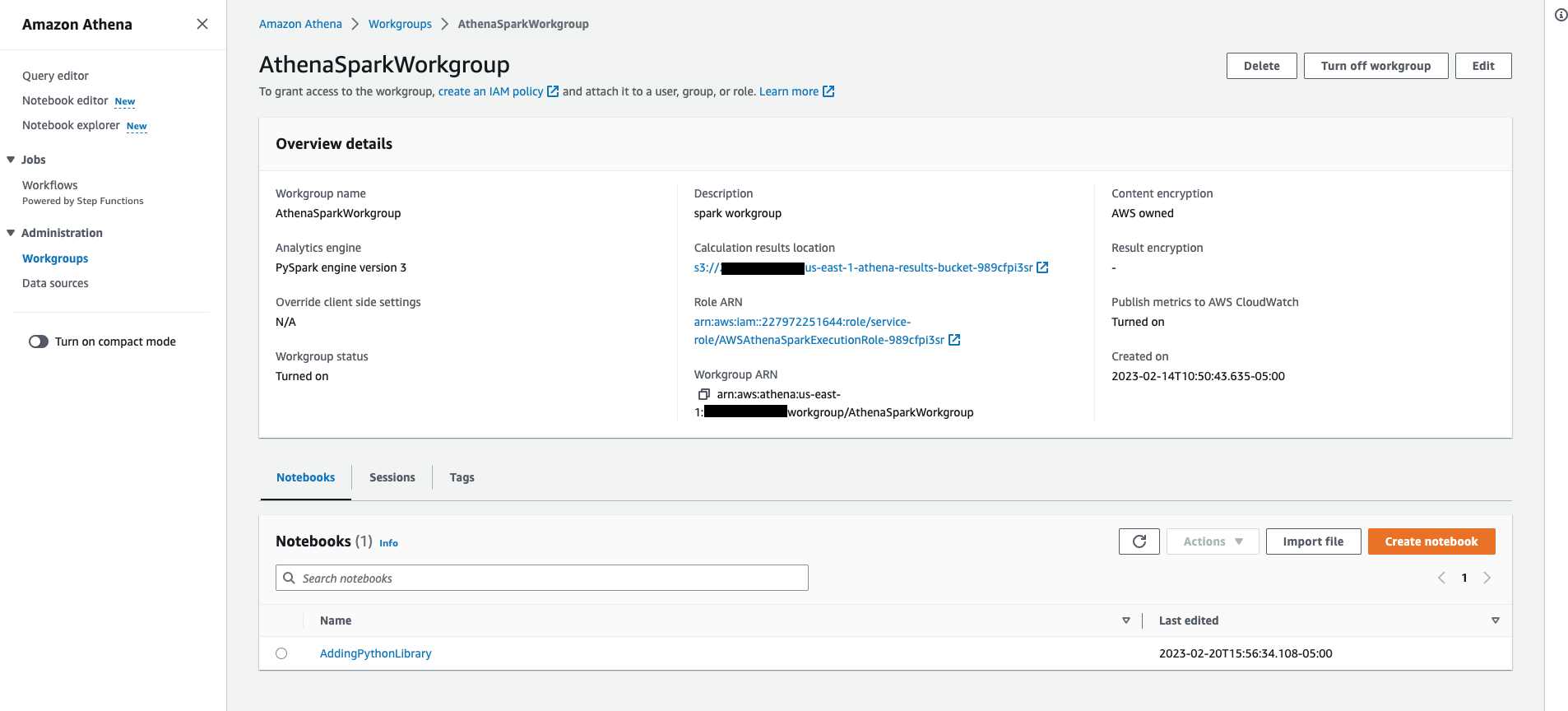
-
Nhấp vào Session và lọc ra các phiên dựa trên trạng thái của chúng như Active, Idle, Terminated etc. Bạn có thể khám phá thêm phiên và chi tiết tính toán bằng cách nhấp vào một trong các phiên từ danh sách.